A mesterséges intelligenciák szünet nélkül változnak. Meglehet, nem tűnik szembe a különbség, azonban ezeket a mély és komplex információhálókat nem csupán adataik, de felhasználási módjaik is meghatározzák. Értékelésük függ a fejlesztőtől és a felhasználótól, de legfőképpen a világ alakulásától. Háromszáz évvel ezelőtt Galilei csillagászati valóságmodelljei áttörőnek számítottak. Meglehet, életében a közvélemény nem értékelte eléggé munkáját és emiatt támadták, azonban tagadhatatlan, hogy végeredményében meghatározta az elkövetkezendő korok tudományos fejlődését.
Napjainkra Galilei mesterséges intelligenciái talán nincsenek már akkora hatással ránk, mint elődeinkre, hiszen több évszázad elteltével belénk ivódott mindaz, ami felépíti, így a továbbiakban nincs szükségünk arra, hogy a hálózatot készen megkapjuk: az adatok szabad áramlásával mi magunk is elkészíthetjük. A mesterséges intelligencia klasszikus formájában apránként nagy eséllyel válik természetes tudássá - legalábbis így volt ez, mielőtt fel nem virradt a digitalizáció hajnala és el nem kezdtek megszületni azon hálózatok, melyek teljes mértékben tőlünk és környezetünktől függetlenül létezhetnek.

Mi a mesterséges intelligencia?
Ha a világot egy hatalmas, adatokból álló, összefüggő információs rendszerként képzeljük el, meg is kaptuk a választ a kérdésünkre.
Az adat nem más, mint atomok vagy fotonok sokasága. Esetleg észrevétlenül terjedő hanghullámok összessége. Érzékszerveinkkel felfogható és fel nem fogható jelenségek, melyek a valóságot alkotják.
Az ember kapcsolatot teremt a környezetével, adatokat keres, információkat alkot, hogy támpontot hozzon létre. Egyszóval értelmet keres. A természetes intelligencia legfőbb jellemzője, hogy gyakorlatilag lehetetlen megjósolni, ki milyen kapcsolatokat vél felfedezni. Fizikai adottságaink és az életünk során szerzett tapasztalatok formálják a piramis alját alkotó, legbonyolultabb hálót, amely személyiségünket alkotja és az erre épülő újabb és újabb kapcsolatokat jelentősen meghatározza.
Van, akit nyugalommal tölt el a vihar előtti csend, a hirtelen felvillanó fényáradat, a friss eső illata és a bőrre lecsapódó pára; ám olyan is van, akiben mindez például haragot kelt, mert még azelőtt, hogy a sötét felhők és az eső közti összefüggésre rálelt volna, átverte a délelőtti napsütés.
A mesterséges és természetes intelligencia között a legnagyobb különbség az, hogy utóbbi esetében hiányzik a piramis alja és szilárd kövek helyett hol fémmel, hol papírral próbáljuk helyettesíteni a darabokat. Meglehet, néhol sikerül egy-két alkalommal helyesen kiegészíteni az építményt, azonban a hibafaktor kiküszöbölhetetlen. Rengeteg munkát és odafigyelést igényel az, hogy saját magunk merőben leegyszerűsített modelljét megkíséreljük létrehozni.
Márpedig, ha számítógépes mesterséges intelligenciáról van szó, voltaképpen ez történik. Több gépi tanulási technika az emberi idegrendszer működésén alapszik (ezek közül eggyel már korábban megismerkedhettünk).
Bonyolult rendszer, hatalmas elvárások
Az eddigiek alapján kijelenthetjük, hogy a mesterséges intelligencia körülhatárolása, gépi fejlesztése és felhasználása nem a legegyszerűbb feladatok egyike. Természetesen digitális környezetben is érvényes az állítás, miszerint nem mindegy, hogyan értelmezzük a valóságot, tehát mely adatokat tartjuk fontosnak, melyeket foglaljuk bele a hálózatba. Így fordulhat elő, hogy egyes esetekben az igények alacsonyak és a cégek megelégszenek a tömegcikkszerű verziókkal is, míg máshol az illetékesek irreális feltételeket szabnak ki fejlesztőik számára.
MI projektekkel foglalkozni versenyfutás az idővel. Szinte elképzelhetetlen, mit tapasztalnak azok, akik a rendszereket mögött állnak, ha még mi, átlagos felhasználók is érzékeljük, milyen gyorsan fejlődik a technológia.
GAFAM: a nagyok
A legnagyobb tech-cégek (Google, Apple, Facebook, Amazon, Microsoft) fejlesztői arról számoltak be, hogy a kiégés egyre nagyobb problémát jelent a szakmában. A legfőbb nehézség, hogy a munkáltatók, követelményeik teljesítésére túl rövid határidőket szabnak meg. Nyilvánvaló a lemorzsolódástól való félelem; minél nagyobb áttörésekre volna szükség, minél kevesebb pénzből, minél hamarabb.
Hatalmas a verseny, amely már nem csupán házon belül okoz gondot. A számítógépes mesterséges intelligenciák tanítása érdekében egyre több példa adódik jogilag megkérdőjelezhető döntések meghozatalára, adatvédelmi- és polgári, illetve szerzői jogok megkerülésére, olykor megszegésére.

Hova tovább?
A jogalkotásban 2024 elején priorizált kérdéskörré vált a digitális mesterséges intelligencia fejlesztésének és felhasználásának szabályozása. Mára az Európai Unió szerzőinek és polgárainak jogait, továbbá adatait külön törvény védi.
Bár a változás természetes következménye a folyamatok lassulása, ez korántsem jelenti a virtuális mesterséges intelligenciák bukását. Jelenleg egy kisebb (ipari) forradalmat élünk, melynek fő mozgatórugója ez a technológia. Már nem lehet csak úgy lemondani róla, így új megoldásokra van szükség.
Jelenleg a generatív mesterséges intelligencia éli virágkorát. Érthető, hiszen izgalmas terület. Tulajdonképpen mesterséges információ (befolyásolt) létrehozásáról van szó - újabban már vizualizált formában is. Dalszerzés, kódolás, szövegalkotás, kép- és videó-szerkesztés - mind-mind olyan feladatok, melyek elvégzésére közel sem hibátlanul, de egyes hálózatok ma már képesek. Ahogyan a McKinsey & Company is sejteti, a közeljövőben az MI orvostudományi felhasználásaival kapcsolatos kutatások mellett valószínűleg a legfontosabb eredmények ezen területen várhatóak.
A legfontosabb területek
A gépi tanulási technikák (pontosabban a deep learning) hatékonyságának felismerésével rengeteg kiskapu nyílt meg; a képzelet határa voltaképpen a csillagos ég. Lényeges azonban, hogy a megvalósítással többnyire várni kell, míg a virtuális mesterséges intelligencia saját maga képes nem lesz megteremti a környezetet a következő szint számára. És hogy mit is jelent ez?
A New York Times 2021-ben beszámolt arról, hogy a Codex már 12 programozási nyelvet ismerve képes kódokat írni. Vajon mi történne, ha a MI ezen technológiával felvértezve képes volna új kézségeket használható formában létrehozni és a saját rendszerébe építeni?
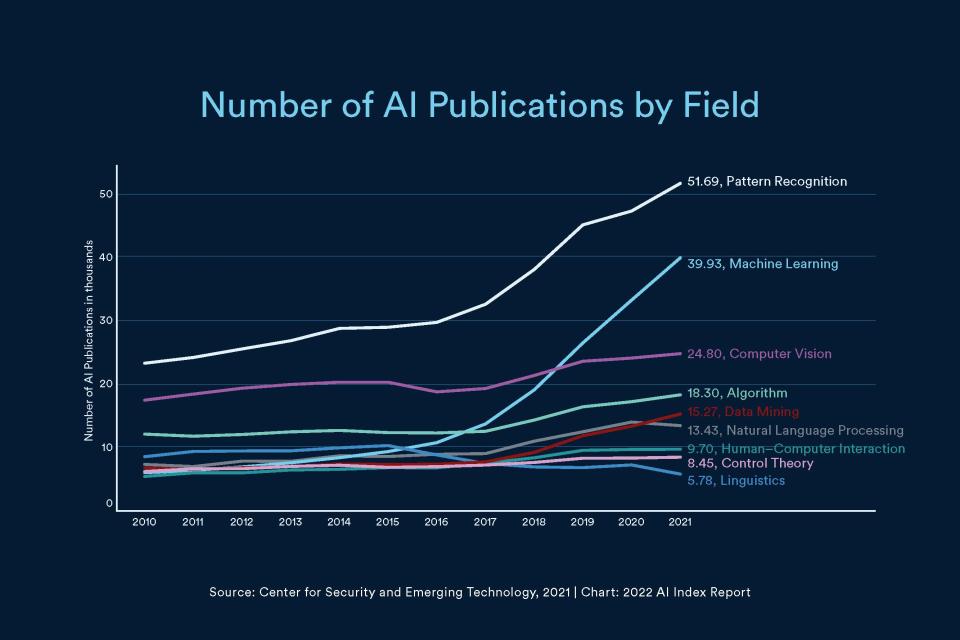
Izgalmas évek elébe nézünk, még akkor is, ha belátható időn belül a digitális mesterséges intelligencia csupán kényelmi funkciókkal tud majd szolgálni. A jelenlegi kutatások merőben meghatározzák majd a tudományterület fejlődési irányát és intenzitását.
Nincsenek megjegyzések:
Megjegyzés küldése