
2021 végén az OpenAI komoly problémával találta szembe magát: elkezdtek elfogyni az interneten szabadon hozzáférhető, feldolgozásra váró angol nyelvű szövegek. Ahhoz viszont, hogy a mesterséges intelligencia (továbbiakban: MI) a következő szintre emelkedhessen, több információra volt szükség. Sokkal többre.
A fejlesztők ennek orvoslására 2022-ben létrehoztak egy beszédfelismerő eszközt, a Whisper-t, amely képes élőbeszédet írott szöveggé átalakítani. A cég példájára többek között a Google is hasonló projektbe kezdett, de vajon miért szánták el magukat a vállalatok egy ilyen, több fronton is megkérdőjelezhető döntés meghozatalára? És mit szóltak ehhez a tartalomgyártók?
Először is ahhoz, hogy megértsük, miért kockáztattak ekkorát, meg kell ismerkednünk a szavak erejével.
A manapság népszerűvé vált mesterséges intelligenciák elsősorban írott formában, lexémákkal kommunikálnak. Általuk tanulnak, velük dolgoznak; egységesítésük tárgyát képezik. A rendszer kulcsfontosságú szereplője a nyelvet inputként és outputként is használó természetes nyelv-feldolgozó (Natural Language Processing; NLP) technológia - fontos észben tartani, hogy tulajdonképpen már ez önmagában egy MI, amelyet egyebek mellett a Google Cloud, illetve a ChatGPT is használ.
Miként hasznosítja az MI a szavakat?
A mesterséges intelligenciák számos tanulási technika alkalmazásával fejlődhetnek. A legnagyobb áttörést a deep learning megjelenése eredményezte, amely többek között a képfelismerést és a szöveg képpé alakítását is magával hozta. A Szegedi Tudományegyetem bejegyzése alapján a módszer mesterséges neurális hálózatokat használ (Neural Networks), melyek tulajdonképpen az emberi agy információfeldolgozásának működésén alapszanak. A megannyi, együttműködő processzáló elem (neuron) végzi a számítások alapegységeit. A hálózatok rétegekből épülnek fel. Az információ csak rétegről rétegre, egy irányba - az input (bemeneti) rétegtől az output (kimeneti) réteg felé vagy fordítva terjedhet.
A neurális hálózat tanítása
A folyamat során a cél, hogy a legutolsó, output rétegre érve minimalizáljuk a hibát - minél közelebb kerüljünk az elvárt értékhez.
A deep learning olyan hálózatokat takar, amelyekben több rejtett réteg található (ezért "mély"). Az egyes rétegek a nyers adat különféle reprezentációját képesek megalkotni, akár fokozatosan részletekbe menően. A klasszikus gépi tanulási (machine learning) módszerektől eltérően ebben az esetben nincs szükség előzetes jellemzőkinyerésre, mivel azokat a részletek elemzésével a rendszer képes magától is kiválasztani.

A "mély tanulás" két ismert fajtája a rekurrens neuronháló (Recurrent Neural Network; RNN), illetve a konvolúciós neurális hálózatok (Convolutional Neural Network; CNN). Az RNN visszacsatolással működik; képes emlékezni az eggyel korábbi állapotra is. Főként természetes nyelvek feldolgozására, beszédfelismerésre alkalmazzák, mivel kiemelkedően jók a kontextus megértésében; szövegek generálásában és lefordításában.
A konvolúciós hálózatokban tömörítésre kerül a bemeneti információ. Főként tárgyfelismerésnél van szerepük. A bemeneti adatot tulajdonképpen minden réteg más és más kritériumok alapján bontja elemeire.
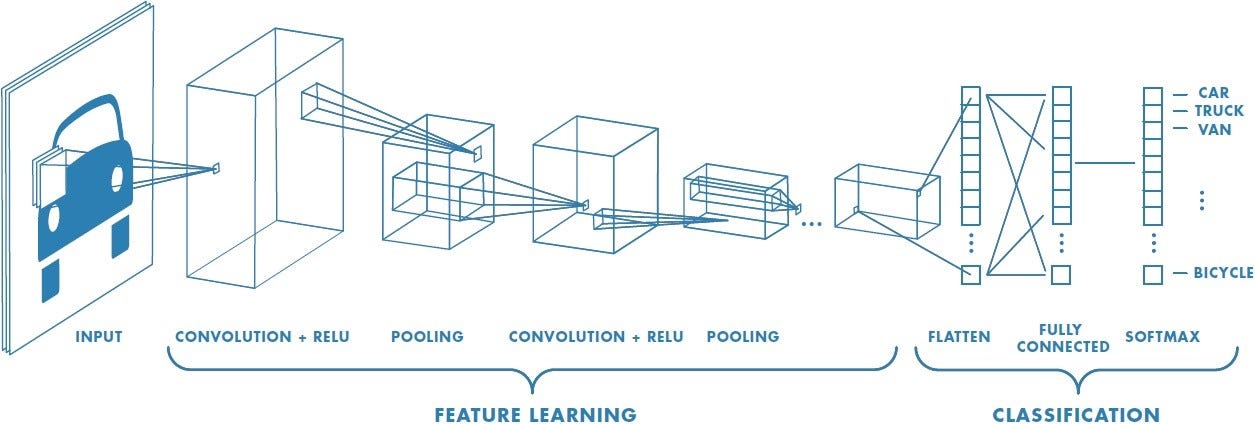
Az MI működéséhez...
mindenekelőtt szükség van bemeneti (input) adatokra, melyek jelen példában legyenek szavak. Ezek begyűjtésre kerülhetnek többek között szövegből vagy akár hangfelvételből is. Kiválasztás után kategorizálásra kerülnek, tegyük fel aszerint, hogy az algoritmus képes-e értelmezni őket, avagy sem. Végül létrehozhatjuk a kritériumot, amely alapján az adatok feldolgozásra, illetve felhasználásra kerülhetnek.
Feldolgozás során az MI-nak megengedhetjük, hogy eldöntse, mihez kezd az információkkal. A rendszer kiválogatja őket a már tanulás céljából belé programozott minták alapján, majd értékeli az eredményeket. Ha egy adatkészlet "hibaként" jelenik meg, akkor az MI tanul belőle és a folyamat különböző feltételek mellett megismétlődik. Előfordulhat, hogy szükséges változtatásokat alkalmazni az algoritmus szabályain, ehhez vissza kell térnünk az eredményekhez.
Az utolsó lépés az értékelés. Ekkor az MI szintetizálja a kapott információkat, hogy előrejelzéseket készíthessen (figyelembe véve az eredményeket és változtatásokat).
Mi történik, ha elfogy a szöveg?
A különféle mesterséges intelligenciák által feldolgozott szómennyiség lenyűgöző. A New York Times szerint a legnagyobb chatbot rendszerek körülbelül három trillió szót dolgoztak már fel, amely nagyjából kétszer annyi, mint amennyi megtalálható az Oxfordi Egyetem Bodleian Könyvtárában – noha az intézmény már 1602 óta gyűjti a dokumentumokat. Ennek eredményeképpen a tech cégek aggodalmukat fejezték ki, ugyanis a kiváló minőségű internetes információforrások (ide sorolhatók a hozzáférhető könyvek, cikkek, tanulmányok stb.) feldolgozása előreláthatólag 2026-ra lezárulhat. Az MI olyan gyorsasággal dolgozza fel az adatokat, hogy ezzel az emberek képtelenek lépést tartani.
Nincs írott tartalom? Csináljunk!

Hogy az adatokhoz hozzáférhessenek, az olyan tech vállalatok, mint a már említett OpenAI, a Google, illetve a Meta, átléptek bizonyos határokat, figyelmen kívül hagyva az egyes platformok irányelveit. A Google egykori nyilatkozata szerint az MI modelljeik csupán olyan Youtube tartalmakat vettek figyelembe, amelyek alkotóival a cég megegyezett - olvasható a New York Times összefoglalójában.
De vajon minden tartalomgyártó tisztában volt azzal, milyen munkálatok folytak a háttérben?
A válasz az, hogy nem. A szoftverek fejlesztése céljából történő adatkinyeréseknek sokáig semmiféle irányelv nem volt megszabva, így fordulhatott elő, hogy a tavalyi év során többek között a New York Times is pert indított az OpenAI és a Microsoft ellen (bővebben).
2023 júniusában a Google egy időre megváltoztatta adatvédelmi és általános szerződési feltételeit. A cég ekkor nem csupán egyes felhasználók munkáit használta fel az általuk fejlesztett mesterséges intelligenciák tanítására, hanem minden nyilvánosan hozzáférhető tartalmat, amely elérhetővé vált a Google Dokumentumokban, Táblázatokban és egyéb alkalmazásokban. Ahogyan az várható volt, a hírt nem sokan fogadták kitörő örömmel; szerencsére mára ilyen jellegű felhasználásról nem tájékoztatnak a feltételek.
Hogyan tovább?
A jogi viták és egyre szélesebb körű szabályozások (lsd. az Európai Unió megállapodása a mesterséges intelligencia alkalmazásáról) napról-napra nehezítik a fejlesztők munkáját. Ennek eredményeként mára már a szintetikus adat (tehát nem emberek által előállított; kép; zene; videó stb.) is elterjedőben van.
Jelenleg a legnagyobb adatmennyiséggel rendelkező nagy nyelvi modell a 2024. március 27-én megjelent DBRX, amely a szabadon hozzáférhető mesterséges intelligencia szoftverek közül gyakorlatilag minden lényeges kritériumot illetően kitűnik.

Nincsenek megjegyzések:
Megjegyzés küldése